BENCHMARK Apps
These benchmark applications are adapted from dreamlab RIOT benchmark, and are intended to be used to test the different functionalities of the ThingsJS platform such as task scheduling. Everything can be found in samples/IoTBench/.
Details
There are four benchmark applications: ETL (extract, transform, and load dataflow), STATS (statistical summarization dataflow), TRAIN (model training dataflow), and PRED (predictive analytics dataflow). The data comes from a .csv file containing 1000 lines of taxi data. For our implementation, each component along the dataflow communicates through MQTT.
Directory structure
IotBench
│ Spout.js - needed for all benchmarks
│ Parse.js - needed for all benchmarks
│
└───/ETL
│ |...all files for ETL benchmark
└───/PRED
│ |...all files for PRED benchmark
└───/TRAIN
│ |...all files for TRAIN benchmark
└───/STATS
│ |...all files for STATS benchmark
└───/scripts - for benchmark measurements etc.
│
└───/Data - all data files needed for benchmarks
| | TAXI_properties.json -
| a properties file for all the
| benchmarks. Please ensure
| paths pointed by this file exist
| locally (if you aren't using GFS) or
| globally (if you are using GFS)
│
└───/Models - all models needed for benchmarks
ETL:
Filters and transforms sensor data before returning the data into SenML format once again.
Notes:
- The interpolation component does no transformation for the taxi dataset (see here for more information)
- The external npm package
bloomfilteris used in the bloom filter component- The Join component has been omitted
- All components in the ported dataflow already communicate through MQTT, and therefore the MQTT Publish component is omitted due to redundancy

STATS:
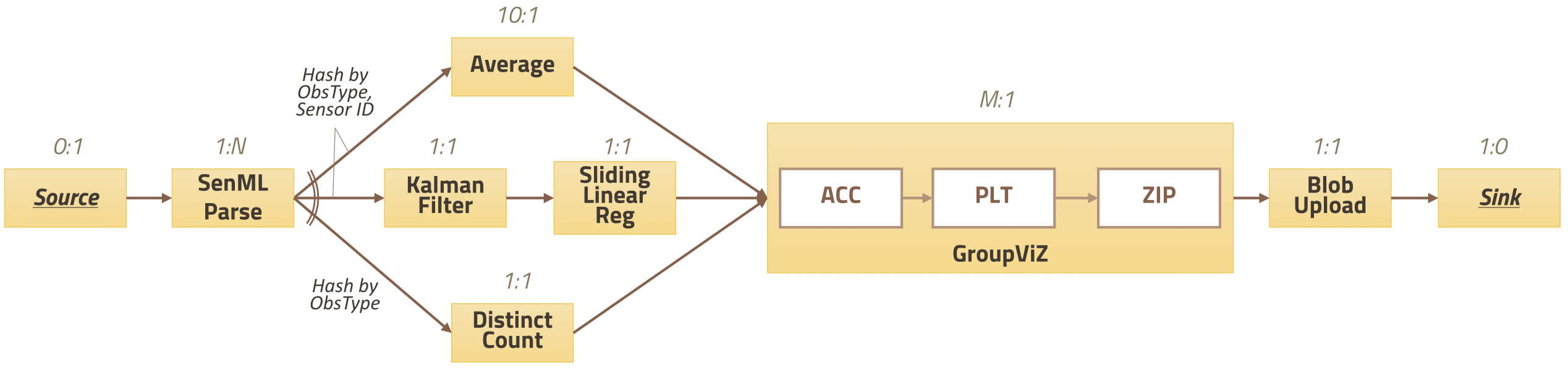
Performs numerous statistical summaries for a dataset and fits a simple linear regression model.
Notes:
- The adapted GroupVIZ block creates a static webpage that displays a dynamic plot of the accumulated statistics
TRAIN:
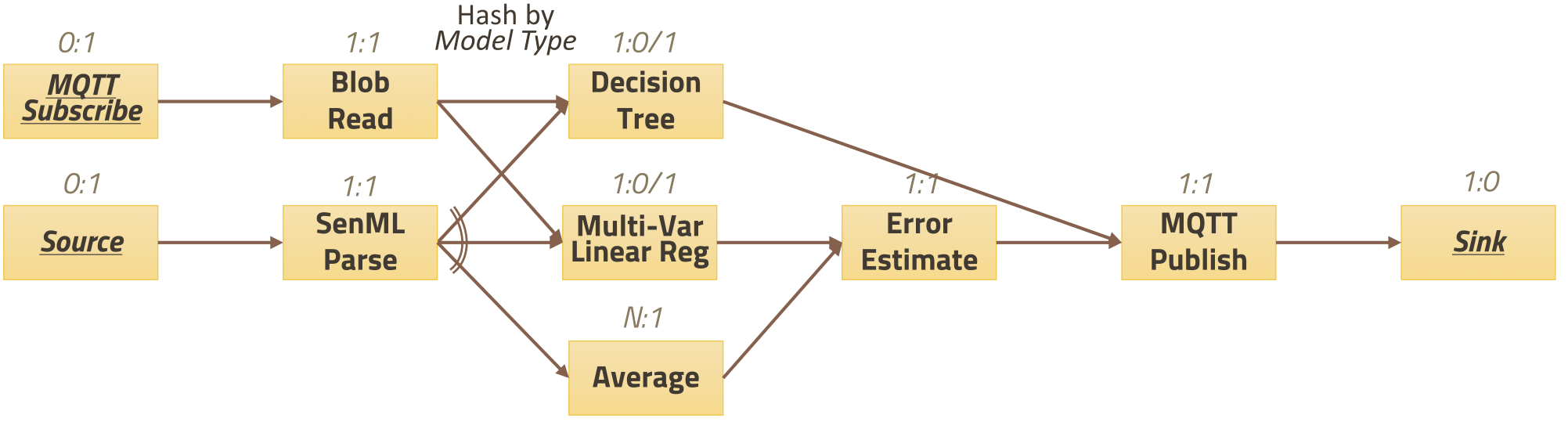
Trains a regression tree and multi-variate model, with the option of saving these models to the global filesystem.
Notes:
- The external
C4.5npm package is used in place of Java'sJ48implementation of the C4.5 decision tree- The npm package
ml-regression-multivariate-linearis used for training

PRED:
Fetches trained models saved in a filesystem (either locally or globally), and does predictions on the incoming data before calculating the residual error.
Notes:
- On the taxi dataset, the prediction is on the taxi fee
Scheduling Benchmarks
Instead of individually scheduling every component for each benchmark, we plan to use the ThingsJS Scheduler to dispatch these components automatically. The distribution of these tasks on workers can be based on each component's required memory, CPU, bandwidth, etc., decided by the scheduling algorithm used.
User Guide
To run these benchmarks on a ThingsJS worker, users must have the appropriate dependencies.
- In the directory the worker is to run in, make sure it has been linked to
ThingsJSusing the commandnpm link things-js. Also ensure there is apackage.jsonfolder in the directory (this may just be an empty file) - If using the global filesystem, ensure that all datasets have been saved on the filesystem. Otherwise, make sure all datasets are saved in the worker directory
A script is provided to automatically trigger the scheduling of a benchmark (provided there exists at least one running worker and a scheduler present). The command is:
node benchmark.js <ETL/STAT/TRAIN/PRED>
Gathering Measurements
There are two scripts that currently gather data for these benchmarks, one for resource usage, and the other for line processing rate. These scripts can be found under samples/IoTBench/scripts.
Resource Usage
To gather information about the resource usage for each component in the dataflow of a benchmark, run the command:
node resource_measurement.js <cpu|memory|total>
Try to run this script as close as possible to when the benchmark is launched to avoid capturing irrelevant data.
- The data will be saved locally to a .csv file
- You can either choose to capture CPU, memory, or both CPU and memory usage for the benchmark components
Line Processing
To gather information about how fast each line of data is being processed in the dataflow for any of the benchmarks, run the command: node time_measurement.js before launching a benchmark. This script will capture and accumulate the time measurements for how fast each component is processing a single line from the original source data.
To save this information locally, run the command
node time_measurement.js > filepath
The data captured by this script is in the following format:
<line number(s)> <component name> <processing time in ms>
and also
Total <line number> <total time in ms> to indicate how long the line took to process through the entire dataflow.
All figures referenced from dreamlab RIOT benchmark